
# 反转链表
# 链表基础
基本概念: 链表是一种常见的线性数据结构,通过一系列的节点来表示元素,每个节点包含数据和指向下一个节点的引用。与数组相比,链表在内存中不要求连续存储,允许动态的插入和删除操作,使得它在某些场景下更为灵活。
主要组成部分:
- 节点(Node): 是链表的基本单元,包含数据和指向下一个节点的引用。
- 头指针(Head): 是链表的起始节点,用于标识链表的入口。
- 尾指针(Tail): 指向链表的最后一个节点,其下一个节点指向空值(null)。
类型及特点:
- 单链表(Singly Linked List): 每个节点只有一个指向下一个节点的引用。
- 双链表(Doubly Linked List): 每个节点有指向下一个节点和前一个节点的两个引用,提供了双向遍历的能力。
- 循环链表(Circular Linked List): 尾节点指向头节点,形成一个环。
基本操作:
- 插入(Insertion): 在链表中插入一个新节点,调整节点的引用关系。
- 删除(Deletion): 从链表中移除一个节点,重新连接相邻节点的引用。
- 查找(Search): 遍历链表,定位特定元素的位置。
- 遍历(Traversal): 顺序访问链表的所有节点,获取其中的数据。
使用场景:
- 当需要频繁执行插入和删除操作时,链表相较于数组更为适用。
- 需要动态分配内存,而不是在开始时就确定数据大小。
- 在内存空间不连续的情况下,链表能够更灵活地组织数据。
优点:
- 动态性: 链表长度可以动态增长或缩小,不受固定大小的限制。
- 插入和删除效率高: 相比数组,链表对于插入和删除操作更为高效。
- 不需要预先分配内存: 节省了内存的使用,可以在运行时动态分配。
# 反转链表
反转链表并返回新头部,如下链表:

反转后:

# 实现
单向链表
type Node struct {
Value int
Next *Node
}
func ReverseLinkedList(head *Node) *Node {
var pre *Node
var next *Node
for head != nil {
next = head.Next
head.Next = pre
pre = head
head = next
}
return pre
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
双向链表
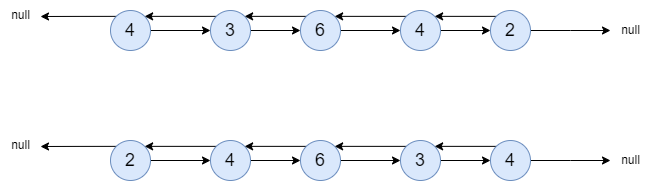
上图展示了反转前与反转后的结构体,方便带入码实现
type DoubleNode struct {
Value int
Next *DoubleNode
Last *DoubleNode
}
func ReverseDoubleLinkedList(head *DoubleNode) *DoubleNode {
var pre *DoubleNode
var next *DoubleNode
for head != nil {
next = head.Next
head.Next = pre
head.Last = next
pre = head
head = next
}
return pre
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18