
# 解析服务实践
用例库脚本非常的庞大达到3.5G,如果一次性解析全部的节点,并向用户展示,则花费时间相当长,用户需要等待近2分钟才可以选择用例,如树形组件所示:
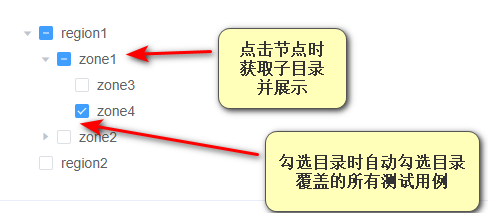
- 一次性解析时间过长,采用持久化方案,提供查询接口
gerrit代码库界面里的点击目录展开的操作达到了8S,因为代码库过大- 采用持久化方案,提供查询接口
# 穿刺算法选择
# 场景
实际项目目录:
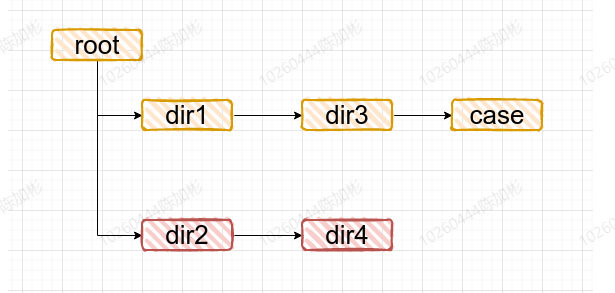
访问web网页选择当前项目后:
网页展示当前目录的目录,初始默认展示前两级
- root - dir1 - dir21
2
3点击
dir1后- root - dir1 -dir3 - dir21
2
3
4点击
dir3后- root - dir1 -dir3 - case - dir21
2
3
4
5采用逐级展开的方式,要求速度要快
# 方案
# 采用持久化:
nodes: [
{"name":"root", "nodeId": "0", "pNodeId": "", "type": "dir"}
{"name":"dir1", "nodeId": "1", "pNodeId": "0", "type": "dir"}
{"name":"dir3", "nodeId": "3", "pNodeId": "1", "type": "dir"}
{"name":"case", "nodeId": "6", "pNodeId": "3", "type": "testcase"}
{"name":"dir2", "nodeId": "2", "pNodeId": "0", "type": "dir"}
{"name":"dir4", "nodeId": "4", "pNodeId": "2", "type": "dir"}
]
// 点击目录 dir3 的时候,获取到 dir3的nodeId
// 请求后端接口用dir3的nodeId,作为pNodeId=dir3Id,的查询条件,查询出结果返回给前端展开
2
3
4
5
6
7
8
9
10
# 算法选择:
生成节点持久化的时候,需要遍历我们的目录文件获取信息,而遍历算法在树状的结构中,分为两种:
- 宽度优先遍历
- 深度优先遍历
使用宽度优先遍历?
优势:
- 非递归,采用自己实现的队列结构,不会出现栈溢出的问题。
- 在一般场景下占用的内存较大,维持每层的节点队列。
劣势:需要有一定的代码基础,相对于递归版本的深度优先遍历,较难理解
使用深度优先遍历?
优势:
- 前期可采用递归的方式,代码更易理解。
- 深度优先可先收集叶子节点信息,从而有更大的拓展性
劣势:递归的方式下有可能存在栈溢出的问题,但是可改非递归版本。
暂时使用深度优先遍历代码示例:
type Parser struct {
nodes []string
}
func (p *Parser) parse(path string) {
p.parseProcess(strings.Split(path, "/"), uuid.new())
}
func (p *Parser) traversalProcess(pathList []string, myUuid string) {
// 如果是文件,则使用文件解析实例解析,并且依赖接口方便拓展
// 根据路径获取到子文件
files := dir.List(pathList)
// 遍历所有子文件
for fileName := range files {
// 添加下一级路径
pathList = append(fileName)
// 递归处理所有的节点,可设置返回值,根据返回值做一些特殊处理
p.parseProcess(pathList, uuid.new())
// 回退路径,防止影响下一个文件
pathList = pathList[:len(pathList)-1]
}
// 收集当前节点的名称
p.Collect(pathList[-1])
}
func (p *Parser) Collect(node string) {
p.nodes = append(p.nodes, node)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
将解析算法抽象成接口?依赖接口,方便算法替换。
用例数量:
77548,节点总数:105712,怎么辅助分析我们的深度遍历解析出来的节点是正确的?// 提取节点成结构体 type node struct { name string paht string } // 格式化打印节点树 func (p *Parser) FormatPrint() { for _, n := range p.nodes { FormatPrint1(len(strings.Split(n.Path, string(os.PathSeparator)))-2, n.Name + " " + fmt.Sprintf("%+v", n.Tag), 40) } } func FormatPrint1(level int, name string, formatLen int) { rightLen := formatLen - len(name) fmt.Println(GetSpace(level*8) + name + GetSpace(rightLen)) }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17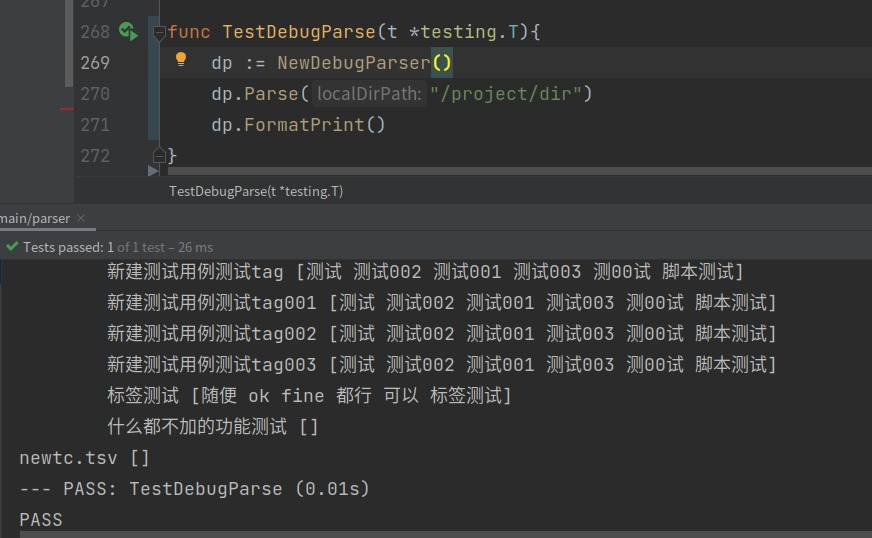
为什么不写测试用例?深度遍历没有很复杂,通过上面打印树状结构,即可看出来对不对。(主要还是自信)
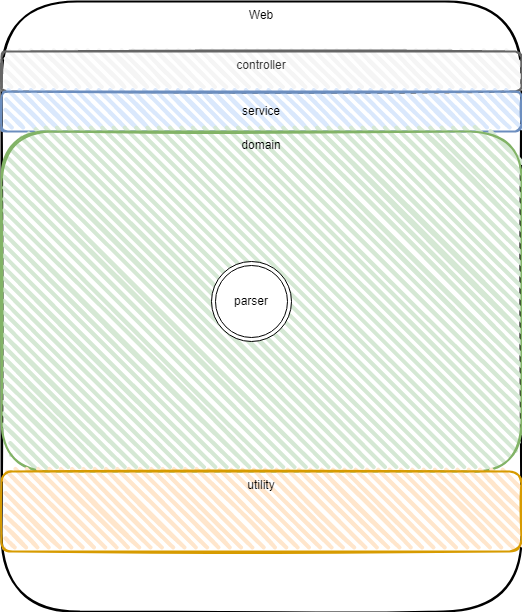
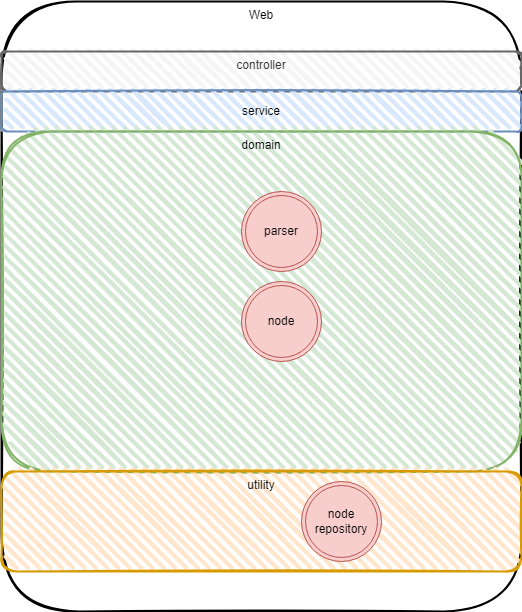
DDD分层
穿刺阶段暂时只有一个解析的实例,先放在领域层
# 持久化方案
节点解析过程中,我们会收集节点,节点如何做持久化呢?
type Parser struct {
nodes []string
}
func (p *Parser) Collect(node string) {
p.nodes = append(p.nodes, node)
}
func (p *Parser) Persistence(node string) {
// 一把持久化节点
// 分批持久化节点
// 调用仓储持久化
}
2
3
4
5
6
7
8
9
10
11
12
13
- nodes 列表过大,十几万个节点常驻内存,垃圾回收性能低
- 解析完才持久化,为什么不便解析边持久化呢?
# 并发持久化
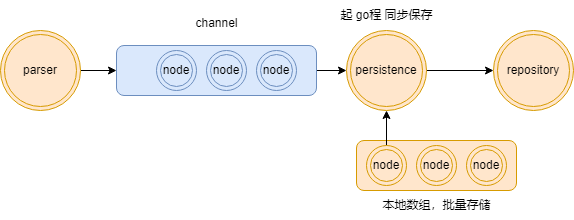
- 为了提高性能,我们起协程做持久化,通过
channel,来传输节点做持久化。没有使用过go语言的话,暂时可以将channel理解为消息队列。 - 通过
channel协同,在保持一个本都长度为1000的数组,做批量存储,当数组放满节点时,将所有节点做一次持久化。
部分代码映射:
type Parser struct {
Res chan *node.Node // channel 节点通信
Done chan string // 是否解析完成,解析完成的话,持久化协程需要退出
LibId string
NodeRepo *node.NodeRepository // 持有仓储做持久化
Lib *lib.Lib
mu sync.Mutex // 并发下的锁
wg *sync.WaitGroup
insertIndex int
nodePool []*node.Node // 本地数组
isDebug bool // 是否是调试模式
DebugRes []*node.Node // 调试节点
}
func (p *Parser) Parse(localDirPath string) {
pathList := dir.ToPathList(localDirPath)
if p.isDebug {
p.PreProcess(pathList, []string{}, utility.GetUuidByString(pathList[len(pathList)-1]), 0)
} else {
go p.PreProcess(pathList, []string{}, utility.GetUuidByString(pathList[len(pathList)-1]), 0)
// 同步持久化,持久化完毕后,Parse 函数才退出
p.Persistence()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
node 结构体
type Node struct {
// ------- 目前阶段需要用到的字段-------
NodeId string `bson:"nodeId" json:"nodeId"` // 随机生成
PNodeId string `bson:"pNodeId" json:"pNodeId"` // 父节点的id
Name string `bson:"name" json:"name"` // 目录/用例名称
Tag []string `bson:"tag" json:"tag"` // 用例标签
Type string `bson:"type" json:"type"` // 节点类型,区分用例还是目录
Path string `bson:"path" json:"path"` // id路径,为了应对重命名时,我们不改变id,对于路径节点的修改我们不需要动全部节点,否则路径上的节点都要修改
// ------- 后续需求拓展字段-------------
TestCenterCaseIds []string `bson:"testCenterCaseIds" json:"testCenterCaseIds"`
Content string `bson:"content" json:"content"`
NamePath string `bson:"namePath" json:"namePath"` // 当前节点的相对路径
PNamePath string `bson:"pNamePath" json:"pNamePath"` // 父亲节点的相对路径
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
DDD分层
# 用例库实体
解析的核心功能已经穿刺完毕了,需要提供那些接口?
- 支持不同项目接入,所以需要让用户自己定义配置自己的用例库。
如何确定唯一的用例库?
gerritUrl+branch
有哪些方法?
lib.Dir()返回项目根目录,根目录在项目根目录下创建自身id的文件夹,防止不同分支打架lib.Pull()在自身目录下拉取代码lib.UpdateAccount()修改密码等等方法..
结构体
type Lib struct {
Id string `bson:"_id" json:"_id"`
GerritUrl string `bson:"gerritUrl" json:"gerritUrl"`
Password string `bson:"password" json:"password"`
Branch string `bson:"branch" json:"branch"`
User string `bson:"user" json:"user"`
}
2
3
4
5
6
7
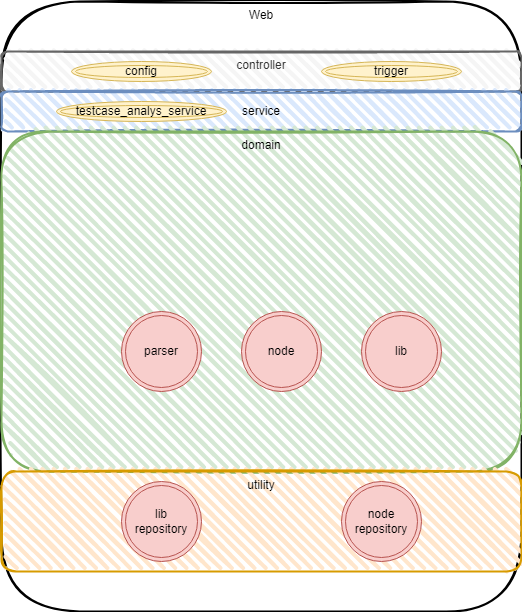
DDD分层
接口层:提供两个接口,
config配置用例库,trigger促发解析用例库service层:testcase_analys_service,组合领域层的对象干活如:触发解析则先实例化
lib找到lib后,使用解析器对lib进行解析
问题
- 没有增量解析,目前还不能上线使用,需要完善增量解析
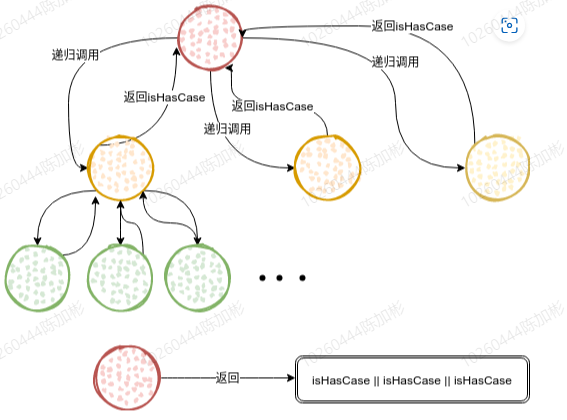
# 优化用例树
新增需求:目录下没有用例的节点不展示。
方案:
- 为我们的递归新增一个返回值,含义为是否包含用例,上层节点根据返回值判断自身是否入库
# 增量解析方案
全量解析已经可行,但是增量解析并未确定,但是用户肯定需要增量解析才可以保证用例库的快速解析。
# 版本一
如何判断增量解析?
如果用例库目录已经存在,则使用
git pull指令,获取变更信息如:domain/{ => execution}/lib/lib.go | 0 // 单纯新增目录 domain/changeanalyzer/{ => 1111}/changeanalyzer.go | 2 +- // 新增目录+修改 domain/execution/lib/case_progress_repo.go | 2 +- // 单纯修改 domain/execution/lib/case_progress_repo1.go | 2 -- // 单纯减少 domain/execution/lib/lib.go | 2 ++ // 单纯增量 domain/{ => execution/abc}/lib/lib.go | 0 // 多层移动 domain/{ a => execution/abc}/lib/lib.go | 0 // 重命名文件无改动1
2
3
4
5
6
7
解决方案
我们使用lib实例,执行git pull 获取到变更信息后,直接给解析器,解析器将变更拆分开来**,遍历每一个变更,到数据库做增删改查**。
以纯新增场景为例:纯新增,遍历路径上的节点,不存在则新建节点入库,直到最后一个节点的时候删除文件,重新解析,解析完毕后,有可能目录下不包含用例,那么之前路径上创建的节点需要释放。释放流程则需要查询父节点之下还有没有其他目录,有的话则父节点保存。
其他场景暂不说明,这种方式有一种致命缺陷,那就是十分的慢,每个变更串行,一次增量解析比一次全解析时间还长
经过分析,我们知道场景非常的复杂,则此时需要构建好我们的测试用例,尽量覆盖所有的变更类型产生的影响,否则一旦代码出现bug,库的数据乱了之后,无法恢复。此时开始以测试驱动我们的开发。
// 1.初始化实体目录
// 写一些工具方法,给一个路径,将路径所有文件创建好,便于初始化我们的测试场景
// 2.使用解析器解析
// 3.比较解析结果与预期
// 依赖数据库需要mock一个数据库出来吗?
// 其他:尽量将我们的用例的字段对其,方便直接拓展
2
3
4
5
6
7
8
9
- 这次开发的用例是开发的基础!!!
- 测试代码几百行,核心代码几十行
# 版本二
经过版本一的尝试和分析,我们发现,其实处理变更还挺麻烦的,我们可以把处理变更的逻辑更内聚一些,于是,我们又有了一个变更分析器。
而且基于之前的经验,变更如果不并发处理,我们没有办法再提升速度
于是变更分析器,我们想要的结果是分好类的变更信息:
{
"增量": ["/A/B/C/x.tsv", "/A/B/C/y.tsv", "/A/B/D/y.tsv"]
"减量": ["/A/B/C/x.tsv", "/A/B/C/y.tsv", "/A/B/D/y.tsv"]
"修改": ["/A/B/C/x.tsv", "/A/B/C/y.tsv", "/A/B/D/y.tsv"]
"移动": ["/A/{B => D}/C/x.tsv", "/A/{B => D}/C/y.tsv", "/A/{B => D}/D/y.tsv"]
"多层移动": ["/A/{B => D/E }/C/x.tsv", "/A/{B => D/E }/C/y.tsv"]
}
2
3
4
5
6
7
func (p *Parser) ParseByChanges(changesMap map[string][]changeanalyzer.Change) {
for cType, changes := range changesMap {
logger.Infof("handle changes: %+v", changes)
switch cType {
case constv.AddType:
p.AddHandle(changes, rc)
case constv.ReduceType:
p.ReduceHandle(changes, rc)
case constv.ModifyType:
p.ModifyHandle(changes, rc)
case ...:
...
case constv.NoChangeType:
logger.Errorf("Hasn't NoChangeType handler !!! change: %+v /n", changes)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
和版本一的效率差不多,只是多了变更分析器,有没有并发方式?
# 版本三
经过了众多尝试,各种场景罗列,考虑各种场景并发下,会出现哪些问题?简直爆炸了。比如:
"/A/B/C/x.tsv ++"
"/A/B/C/y.tsv ++"
// 假设: C 文件夹和 x.tsv y.tsv 都是新增文件
// 那么如果并发执行增量逻辑,就是两个协程同时查询数据库,发现 C 目录不存在,一起入库!导致重复
2
3
4
再比如:
"/A/B/C/x.tsv ++"
"/A/B/C/y.tsv --"
// 要求目录下没有用例则,不需要该目录
// 假设 x.tsv 存在用例,此时删掉x.tsv及其子用例,重新解析x.tsv入库
// 此时 y.tsv 为整体删除,那么我们是不是需要删掉整体的 y.tsv 自身及其子节点,删除的同时,我们可能时最后一个文件,那么他的父节肯定也需要删除。我们可以采用查看父节点的子节点的数量如果为0,则没有用例了,删除自身即可。
2
3
4
5
写完了代码十分的复杂,而且经常测出问题,一出问题全是并发,还不好复现,查个鬼!!!
# 思考
- 类型混合+并发场景太多了,有没有办法化简?
- 有没有一些数据结构或者算法可以帮助我们
增量并发冲突处理,使用字典树+协程:
- 将我们的多个增量变更组成树状结构,让每次判断变成原子操作
- 每个节点可以自身启动协程处理后继节点,将路径变为并发
- 协程太多,
gc压力大?使用第三方协程池
构建字典树+增量解析:
func NewAddParser(changes []changeanalyzer.Change, lib *lib.Lib, rc *ReleaseTaskCollector) AddParser {
ap := AddParser{rc: rc}
ap.root = &DirTireNode{ // 初始化根节点
...
}
ap.size = 1
ap.lib = lib
for _, chg := range changes { // 遍历路径插入字典树
ap.Insert(chg.GetFileRelativePath())
}
ap.PaintSizeProcess(ap.root) // 遍历节点给节点增加子节点数量,用于并发控制
return ap
}
func (ap *AddParser) Insert(path string) {
ps := string(os.PathSeparator)
nodes := strings.Split(path, ps)
cur := ap.root
relativePath := ""
for _, v := range nodes {
if _, ok := cur.Next[v]; ok {
cur = cur.Next[v]
} else {
// 不存在则创建节点
cur.Next[v] = &DirTireNode{
}
// 节点下移
cur = cur.Next[v]
}
}
cur.End = true
}
func (ap *AddParser) Run() {
// 根节点进入队列
var wg sync.WaitGroup
wg.Add(ap.size)
err := routinepool.Pool.Submit(AddNodeHandleWrap(ap.root, &wg, ap.lib, ap.rc)) // 将根节点的任务交给协程池
if err != nil {
logger.Errorf("AddParser run Submit task error: %s", err.Error())
}
wg.Wait()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
变更类型合并
重命名和移动的本质是什么?
domain/{ A => B }/lib/lib.go
// 是不是就等于 domain/A/lib/lib.go 文件删除(删除任务),重新增量解析domain/B/lib/lib.go(增量任务)
2
于是我们有了三种基础类型的操作任务加一种特殊的释放任务:
# 增量任务:
func AddNodeHandleWrap(node *DirTireNode, wg *sync.WaitGroup, curLib *lib.Lib, rc *ReleaseTaskCollector) func() {
return func (){
defer wg.Done() // 当前任务完成
if !node.End {
//处理当前节点的任务,判断当前节点是否存在,不存在创建,存在则返回当前节点的NodeId,继续提交创建任务
HandlePathDir(node, wg, curLib, rc)
} else {
// 叶子节点需要解析tsv文件,解析用例
// 在解析完毕并入库的时候取消在跑的任务,如果不取消,会一直跑不了
HandleLeafNode(node, curLib, rc)
}
}
}
func HandlePathDir(node *DirTireNode, wg *sync.WaitGroup, curLib *lib.Lib, rc *ReleaseTaskCollector){
//处理当前节点的任务,判断当前节点是否存在,不存在创建,存在则返回当前节点的NodeId
nodeId := AddHandleNode(node, curLib.Id)
if nodeId == "" {
for i:=0; i<node.CurSize-1; i++ {
wg.Done()
}
return
}
for _, next := range node.Next {
// 补充子节点信息,并提交子节点任务
next.PNodeId = nodeId
next.ParentIdPath = node.ParentIdPath + string(os.PathSeparator) + nodeId
next.AbsPath = node.AbsPath + string(os.PathSeparator) + next.Name
err := routinepool.Pool.Submit(AddNodeHandleWrap(next, wg, curLib, rc))
if err != nil {
wg.Done()
logger.Error(err)
}
}
}
func HandleLeafNode(fileNode *DirTireNode, curLib *lib.Lib,rc *ReleaseTaskCollector){
// 查询之前是否存在当前文件节点,如果存在需要删除
n, err := node.GetNodeRepositoryInstance().
FindNodeByNameAndPId(fileNode.Name, fileNode.PNodeId, curLib.Id)
if err != nil {
logger.Errorf("Add parser FindNodeChildrenByPath err: %s", err.Error())
return
}
if n != nil {
err = node.GetNodeRepositoryInstance().DeleteNodesCoverNodesWithSelf(n.NodeId, curLib.Id)
if err != nil {
logger.Errorf("Add parser DeleteNodesCoverNodesWithSelf err: %s", err.Error())
return
}
}
// 叶子节点需要解析tsv文件,解析用例
// 在解析完毕并入库的时候取消在跑的任务,如果不取消,会一直跑不了
nP := NewParser(curLib, 10)
pDone := make(chan struct{})
go nP.PersistenceWithSignal(pDone)
if !nP.PreProcess( // 解析tsv,如果没有用例,需要释放上层目录
dir.ToPathList(fileNode.AbsPath),
dir.IdPathToIdList(fileNode.ParentIdPath),
utility.GetUuidByString(fileNode.PNodeId+fileNode.Name),
len(dir.IdPathToIdList(fileNode.ParentIdPath))) {
// 收集释放任务
rc.Collect(fileNode.ParentIdPath)
}
<-pDone
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# 删除任务:
func ReduceWrap(chg changeanalyzer.Change, wg *sync.WaitGroup, cLib *lib.Lib, rc *ReleaseTaskCollector) func() {
return func(){
// 找到第一个不存在的实际目录,并转化为项目相对路径
// 获取该目录,并且删除该目录及其子目录
// 将路径放入 ReleaseTaskCollector[释放任务控制]做统一释放
}
}
}
2
3
4
5
6
7
8
# 修改任务:
func ModifyWrap(chg changeanalyzer.Change, wg *sync.WaitGroup, clib *lib.Lib, rc *ReleaseTaskCollector) func() {
return func() {
// 删除该目录及其子目录
// 调用解析器重新解析
// 判断是否存在用例,
// 如果存在将路径放入 ReleaseTaskCollector[释放任务控制]
// 否则停止
}
}
}
2
3
4
5
6
7
8
9
10
# 释放任务:
func ReleaseWrap(idPath string, libId string) func() {
return func(){
idList := dir.IdPathToIdList(idPath)
var children []map[string]interface{}
var err error
for i:=len(idList)-1; i>=0 ; i-- {
// 从最后一级往前释放
// 如果该节点子节点数量为0 则删除该节点,并向上移动,否则退出
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# 最终解决方案
func (p *Parser) ParseByChanges(changesMap map[string][]changeanalyzer.Change) {
p.wg.Add(len(changesMap)) // 不同类型变更允许并发,设置并发组的数量
rc := NewReleaseTaskCollector(p.Lib) // 释放任务搜集器,将需要释放的最后统一释放
for cType, changes := range changesMap {
logger.Infof("handle changes: %+v", changes)
switch cType {
case constv.AddType: // 并发处理增量变更
go p.AddHandle(changes, rc)
case constv.ReduceType: // 并发处理删除变更
go p.ReduceHandle(changes, rc)
case constv.ModifyType: // 并发处理修改变更
go p.ModifyHandle(changes, rc)
case constv.NoChangeType: // 未知类型日志记录定位
p.wg.Done() // 未知类型直接结束
logger.Errorf("Hasn't NoChangeType handler !!! change: %+v /n", changes)
}
}
p.wg.Wait()
// 最后执行释放任务,防止协程间,由于数据库查询与插入非原子操作,造成误删
rc.RunTask() // 集中释放节点
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
于是我们的领域模型变成了这样:
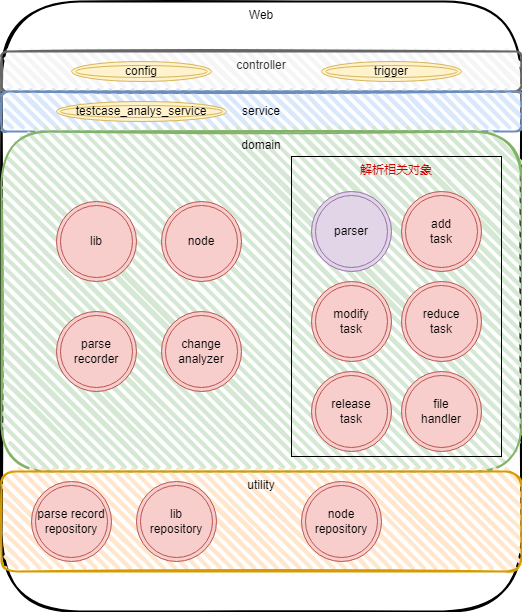
走一遍增量解析场景:
- 用户触发解析
- 服务调用实例化
lib,判断是否已经拉取过代码 - 代码已拉取过,走增量解析,拉取代码,变更信息交给变更解析器处理
- 处理后的变更信息交给解析器走增量解析
# 多实例
解决了上述的问题后,还有一些问题:
- 拉取代码库,直接拉取到微服务容器内部,拉几个大项目微服务被杀死。
- 多个实例并发解析,如果是同一个库可以在不同实例同时解析的话,数组会重复
- 我们的节点id在入库的是随机生成的,用例文件修改后,用例节点重新生成,
id发生变更,一旦修改原本的id会找不到用例。 - 服务升级的时候库解析到一半,已经入库了一些数据,下一次解析怎么保证已入库的数据不再次解析
- 解析接口要求异步,防止链接过多
解决:
- 采用容器数据卷,拉取用例库做持久化,省去服务启动拉取代码的速度,并且防止容器崩溃
- 分布式锁,每个实例需要获取到锁,之后才可以开始执行解析
- 设置节点
id变为根据path做哈希,只要path没变,我们的节点id就不会变 - 加入版本控制,需要记录用例库已经解析的版本,
git diff version1 version2的方式获取 变更信息。获取变更信息后,如果上一次未解析完毕,不会入库最新的解析版本,而是拿到上一次的变更信息重新做一次解析,我们将节点的id设置为唯一索引,则可以保证节点数据不会重复入库。 - 识别出需要保存用例库解析的相关状态数据,添加领域对象
parse recorder解析记录,对应新增一张表
增量解析算法可以再次升级,增量,只需2次数据库 IO
- 我们将增量路径组装成字典树的过程,可是使用节点路径算出当前节点的
id,已经知道所有节点的id,我们可以一把查询路径中所有的节点是否存在,遍历字典树的过程中,判断是否存在的时候就可以不访问数据库了,遇到不存在的节点直接入库即可(还未实现的)
# 我们DDD了吗?
代码的分层看起来和ddd的风格保持了一致,好像ddd了,ddd战术设计中的我们需要识别领域对象、值对象、聚合、服务、工厂等概念。
开发的阶段,对当前问题域的理解还不够透彻,我们在开发的过程中,慢慢的会发现一些实体,然后根据ddd的一些原则,归为领域对象,或者需要仓储,或者需要增加服务。
这个过程是不可避免的,ddd实际上是根据我们对业务问题域理解,划分不同的问题域,将复杂的问题简单化,当问题域够小的时候,我们进行战术设计,来讨论一个微服务内部的划分和组织代码。
在起初,其实我们对业务的理解并不深入,无法识别所有的领域对象,但是还是需要实现功能,我们还是需要写代码解决问题。在这个过程中,写测试用例十分重要,但是一定是"有用的测试用例",crud类的用例,有精力可以写。
测试用例可以在我们识别领域模型之后,我们对模型有重新理解的时候,帮助我们更快的修改模型,并保证功能的正确性,也便于重构。所以我觉的好的测试用例是领域驱动设计的基础,也是代码重构的基础。
# 事件风暴重新设计
# 版本一
- 粒度太粗了,代码几乎无法映射,因为我们对解析的概念十分的不清晰,但是也没又办法,没有人做过,也没有相关的业务专家
# 版本二
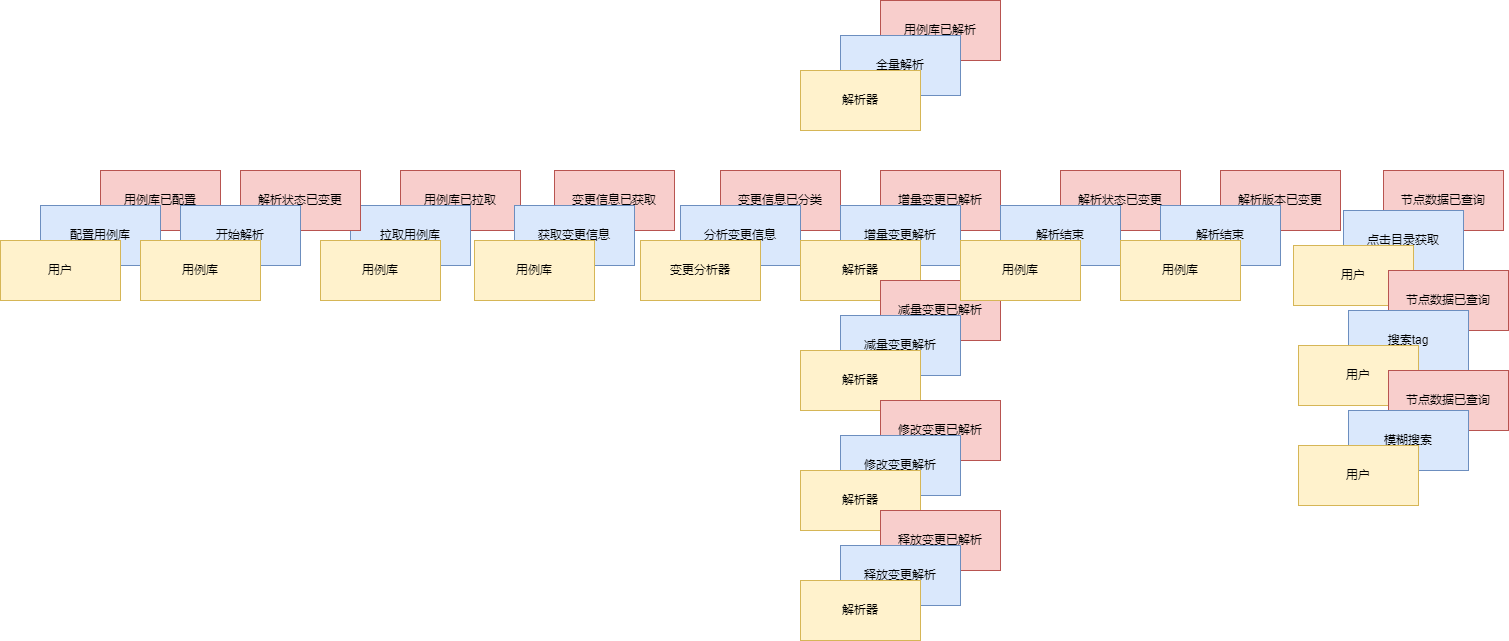
- 使用事件风暴根据业务的行为,梳理出在用例库解析及查询过程中发生的这些行为的所有实体和值对象。
- 从众多实体中选出合适作为对象管理者的根实体,也就是聚合根。
- 根据业务单一职责和高内聚原则,找出与聚合根关联的所有依赖的实体和值对象,构建出一个包含聚合根、多个实体和值对象的集合,这个集合就是聚合。
- 在聚合内根据聚合根、实体和值对象的依赖关系,画出对象的引用和依赖模型
- 多个聚合根据业务和语义和上下文一起划分到同一个限界上下文
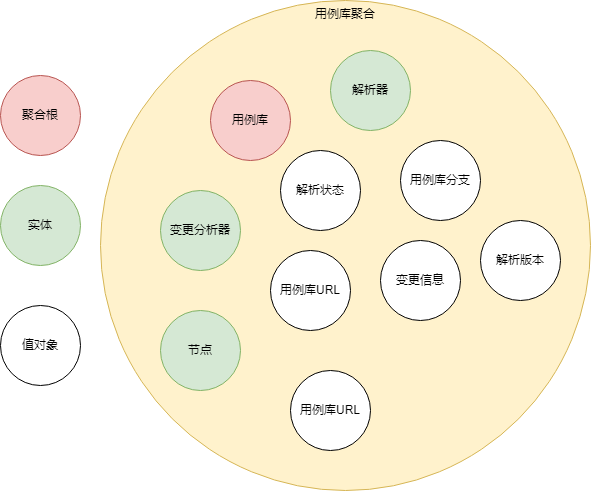
对比之前模型的变化:
- 出现了用例库聚合,聚合根为用例库
- 数据更内聚了,少了解析记录和解析记录仓储
问题:
为什么有例库聚合?没有不行吗?依据是什么?
解析器、变更分析器虽然作为一个实体,但是并不持久化,只做数据处理或计算,很独立,为什么要放在用例聚合中?
在不少数据统计和计算的场景中,很多实体之间相互独立,只参与计算和统计分析,但是这类场景中业务内聚性又很高,你找不出管理这些实体的聚合根。我称这种业务模型为非典型领域模型。虽然在有些方面(比如聚合根)不符合
DDD的一些原则,但是我们也可以按照DDD的方法来完成设计。这么设计之后有什么好处?
- 之前的领域层的实体很多,服务后期还加入了测试执行,执行记录相关的实体,领域模型越来越多,越不好管理,使用聚合分离业务有利于我们维护与拓展。
- 如果我们抽到聚合中,未来用例库解析成为了微服务的瓶颈的时候,可以直接将用例库聚合提取出来,成为一个新的服务
- 聚合作为主要作用是保证聚合内部数据的一致性,虽然当前服务没有一致性问题,但是使我们的数据跟内聚了。我们之前的解析状态分散到解析记录实体中,我们查询状态的时候需要跨越多个表,执行了多次的数据库
io,但是如果在用例库中,可以直接查到。
← UML