
# 数据结构
# 字符串
对应底层数据结构
// src/runtime/string.go type stringStruct struct { str unsafe.Pointer len int } // src/reflect/value.go type StringHeader struct { Data uintptr Len int }1
2
3
4
5
6
7
8
9
10
11字符串本质是一个结构体
Data指针指向底层Byte数组
Len表示的是Byte数组的长度
s := "你好" sh := (*reflect.StringHeader)(unsafe.Pointer(&s)) fmt.Println(sh.Len) // 61
2
3
# 字符串的编码问题
- 所有的字符串均使用Unicode字符集
- 使用utf-8编码
# Unicode
- 一种统一的字符集
- 囊括了159种文字的144679个字符
- 14万个字符至少需要3个字节表示
- 英文字母均排在前128个
# UTF-8
- Unicode 的一种变长格式
- 128 个 US-ASCII字符只需要一个字节编码
- 西方常用字符需要两个字节比如:希腊字母
- 其他字符需要三个字节,如:中、日,韩文
# 字符串的访问
- 对字符串使用len方法得到的是字节数,不是字符数
- 对字符串直接使用下标访问,得到的是字节
- 字符串被range遍历时,被解码程rune类型的字符串
- UTF-8编码解码的算法位于 runtime/utf8.go
# 字符串的切分
- 需要切分时
- 转为rune数组
- 切片
- 转为string
s = string([]rune(s)[:3])
1
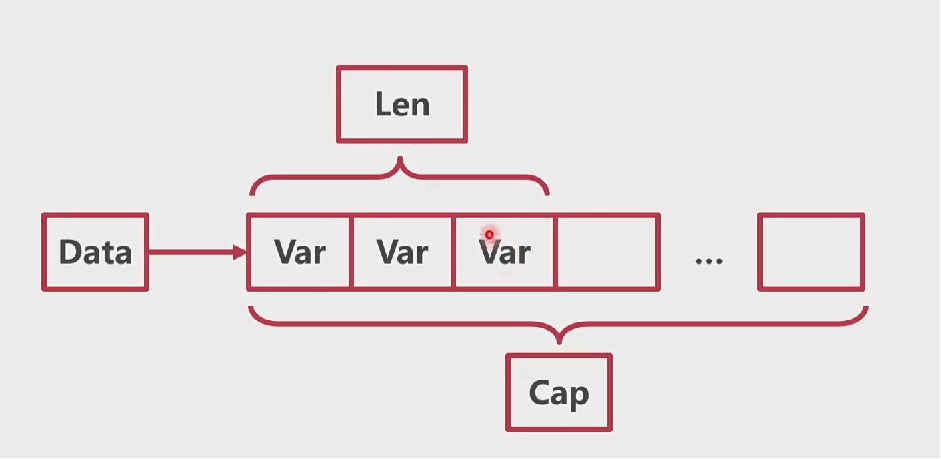
# 切片
长度 24 个字节
// runtime/slice.go type slice struct { array unsafe.Pointer len int cap int }1
2
3
4
5
6本质是对数组的引用
# 切片的创建
根据数组创建
arr[0:3] or slice[0:3]1字面量:编译时插入创建数组的代码
slice := []int{1,2,3}1make: 运行时创建数组
slice := make([]int, 10) // 调用runtime.go/makeslice的方法1
# 切片的追加
不用扩容时,只调整len(编译器负责)
ans = append(ans, 1)1扩容时,编译时转为调用runtime.growslice()
如果期望容量大于当前容量的两倍就会使用期望容量
如果当前的切片长度小于1024,将容量翻倍
如果当前切片的长度大于1024,每次增加25%
切片扩容时候,并发不安全,注意切片并发要加锁
# 总结
- 字符串与切片都是对底层数组的引用
- 字符串有UTF-8变长编码的特点
- 切片的容量和长度不同
- 切片追加时可能需要重建底层数组
# Map
# 重写Redis能用它吗?
# HashMap的基本方案
- 开放寻址法
- 拉练法
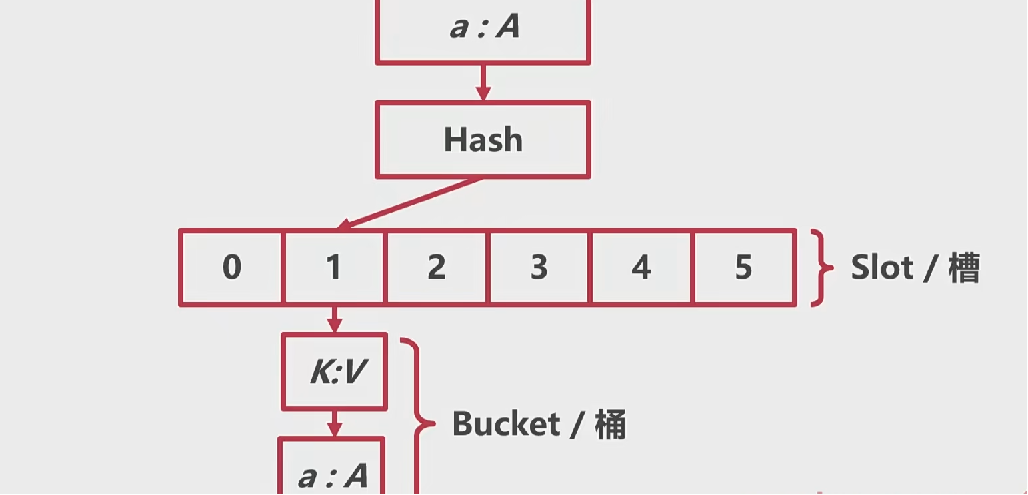
# Go的HashMap
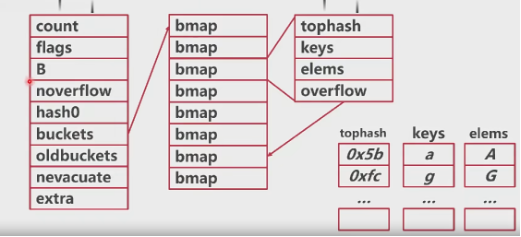
- 对应 runtime/map.go hmap 结构体
# GoMap 初始化
- make
- 字面量
make:
m := make(map[string]int, 10)
1
字面量:
元素少于25个
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
// 等价于
hash = make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
元素多于25个时
hash := map[string]int{
"1": 1,
"2": 2,
"3": 3,
...
"26": 26,
}
// 等价于
hash := make(map[string]int{}, 26)
vstatk := []string{"1", "2", ... , "26"}
vstatV := []int{1, 2, ... , 26}
for i:=0; i<len(vstack); i++ {
hash[vstatk[i]] = vstatv[i]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# Map的访问
计算桶号
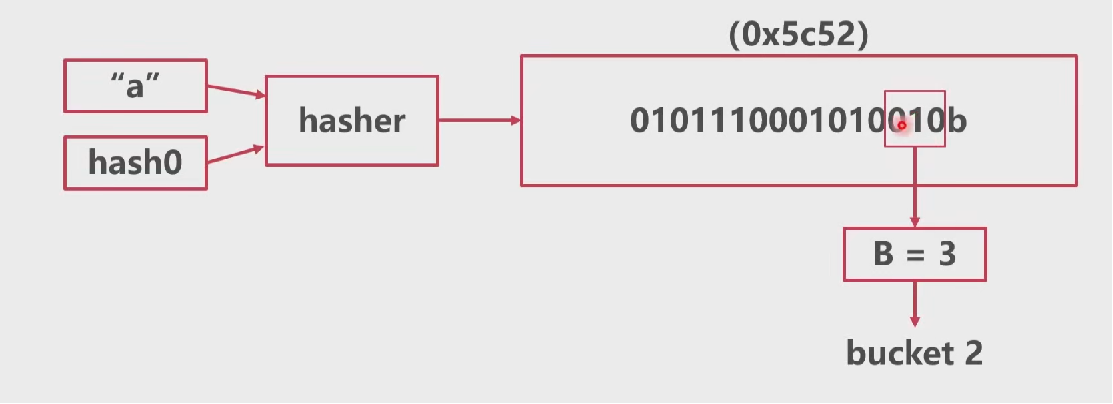
计算tophash
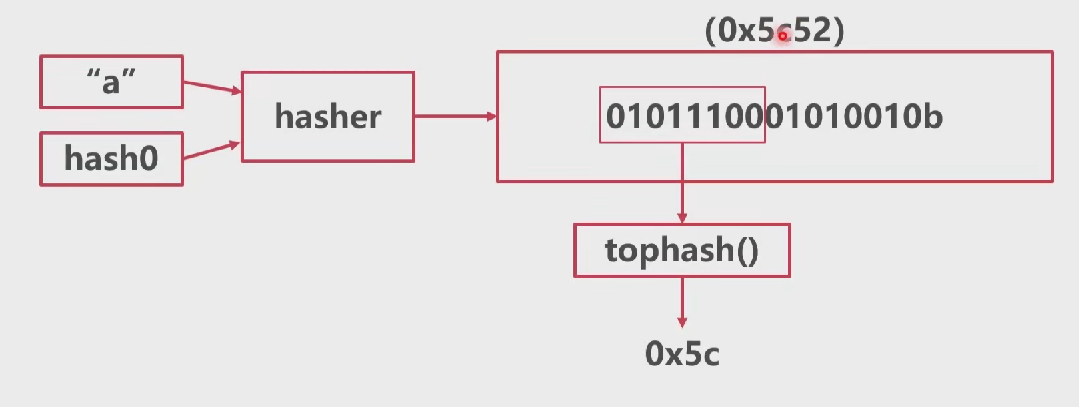
根据值找到元素

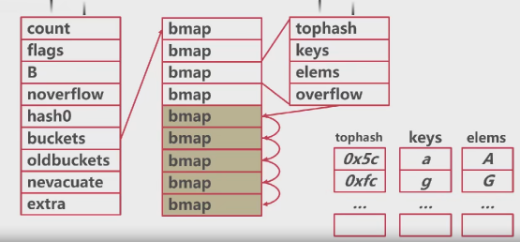
# 总结
- Go语言使用了拉链实现了hashmap
- 每一个同中存储键哈希的前八位
- 桶超出8个数据,就会存储到溢出桶中
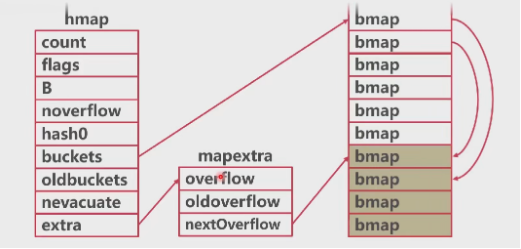
# Map 扩容
哈希碰撞
- map溢出桶太多时会导致严重的性能下降
- map.go/mapassing方法往map中插入数据 637行,触发扩容
- 是否在扩容当中
- 装载因子(装载因子超过6.5,平均每个槽6.5key)
- 使用了太多的溢出桶(溢出桶的数量超过了普通桶)
# map的扩容类型
- 等量扩容:数据不多,但是溢出桶太多了(整理)
- 翻倍扩容:数据太多了
# map扩容
- map.go/hashGrow()
- map.go/mapassing
步骤一:
- 创建一组新的桶
- oldbuckets 指向原有的桶数组
- buckets指向新的桶数组
- map标记为扩容状态
步骤二:
- 将所有的数据从旧桶驱逐到新桶
- 采用渐进式驱逐
- 每次操作一个旧桶时,将旧桶数据驱逐到新桶
- 读取时不进行驱逐,值判断读取新桶还是旧桶
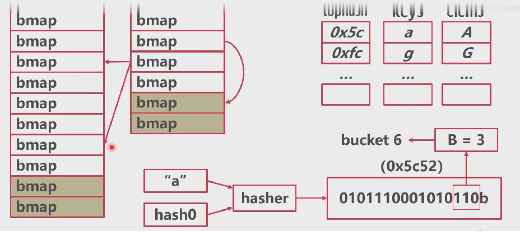
步骤三:
- 所有的旧桶驱逐完成后
- oldbuckets回收
# 总结
- 装载系数太高或者溢出桶的增加,会触发map扩容
- ”扩容“可能并不是增加桶数,而是整理
- map采用扩容采用渐进式,桶被操作时才会重新分配
# 怎么解决Map的并发问题?
func TestStrcut(t *testing.T){
maptest := make(map[int]int)
go func() {
for {
_ = maptest[1]
}
}()
go func() {
for {
maptest[2] = 2
}
}()
select {}
}
// fatal error: concurrent map read and map write
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- map的读写有并发问题
- A协程在桶中读数据时,B协程驱逐了这个桶
- A协程会读到错误的数据或者找不到数据
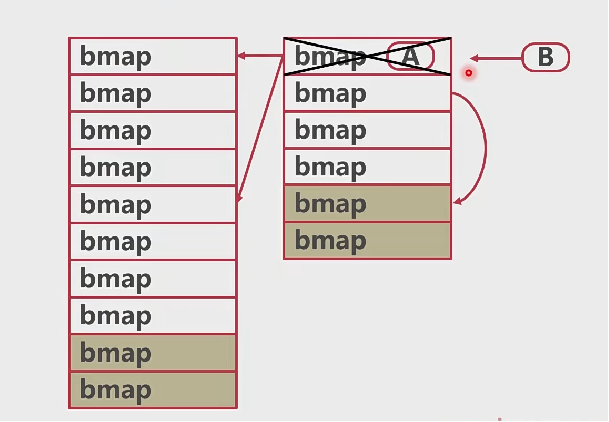
# map并发问题解决
- map加锁(mutex)并发下性能损失巨大
- 使用 sync.Map (做到性能损失可控)
# syncMap
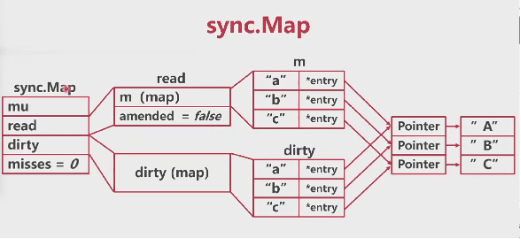
追加时:
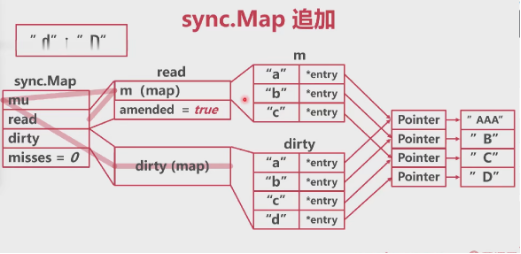
追加读写:

dirty提升:
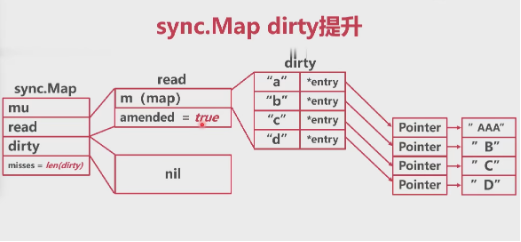
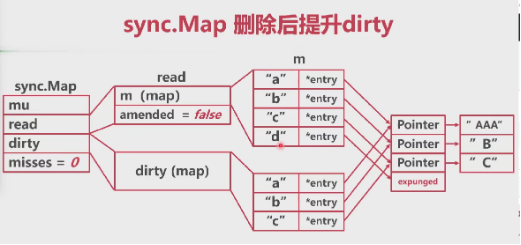
sync.Map 删除
- 相比于查询、修改、新增,删除更麻烦
- 删除可以分为正常删除和追加后删除
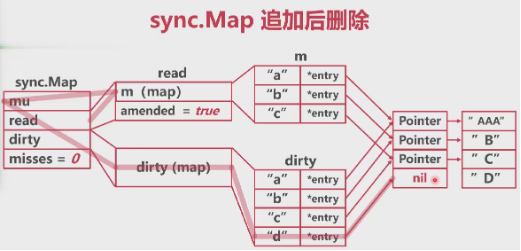
dirty提升情况下:
# 总结
- map在扩容时会有并发问题
- sync.Map 使用了两个map,分离了扩容的问题
- 不会引发扩容的操作(查,改)使用 read map
- 可能引发扩容的操作(新增)使用dirty map
读多追加少的情况sync.Map 性能好,如果追加多的话其实和map性能差距不大。
# 接口:隐式接口好还是显示接口好?
# Go隐式接口的特点
- 只要实现了接口的全部方法,就是自动实现接口
- 可以不在修改代码的情况下抽象出新的接口
# 接口值的底层表示
// runtime/runtime2.go
type iface struct {
tab *itab
data unsafe.Pointer // 万能指针 指向实际的结构体
}
type itab struct {
inter *interfacetype // 接口的类型
_type *_type // 接口的值
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# 类型断言
switch x.type() {
case TrafficTool:
fmt.Println("ok")
}
1
2
3
4
2
3
4
- 类型断言时一个使用在接口值上的操作
- 可以将接口值转换为其他类型值(实现或者兼容接口)
- 可以配合switch进行类型判断
# 结构体和指针实现接口

# 空接口值
// 比接口结构体更简单,只有类型和值,可以表示所有的类型和值
type eface struct {
_type *_type
data unsafe.Pointer
}
1
2
3
4
5
2
3
4
5
- runtime.eface 结构体
- 空接口底层不是普通接口
- 空接口可以承载任何数据
# 空接口的作用
- 空接口的最大用途时作为任意类型的函数入参
- 函数调用时,会新生成一个空接口,再传参
# 总结
- Go的隐式接口更加方便系统的拓展和重构
- 结构体和指针都可以实现接口
- 空接口的值可以承载任何类型的数据
# nil,空接口,空结构体有什么区别?
# nil
// nil is a predeclared identifier representing the zero value for a
// pointer, channel, func, interface, map, or slice type.
var nil Type // Type must be a pointer, channel, func, interface, map, or slice type
1
2
3
4
2
3
4
- nil 是空,并不一定是 ”空指针“
- nil 是六种类型的”零值“
- 每种类型的nil是不同的,无法比较
# 空结构体
- 空结构体是Go中非常特殊的类型
- 空结构体的值不是nil
- 空结构提的指针也不是nil,但是都相同(zerobase)
# 空接口
func TestStrcut(t *testing.T){
var a interface{}
fmt.Println(a == nil)
var c *int
a = c
fmt.Println(c == nil)
fmt.Println(a == nil)
}
// true
// true
// false
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
- 空接口不一定是 ”nil 接口“
- 两个属性都是nil才是nil接口
# 总结
- nil是多个类型的零值,或者空值
- 空结构体的指针和值都不是nil
- 空接口零值是nil,一旦有了类型信息就不是nil
# 实战:内存对齐是如何优化程序效率的?
# 结构体size
func TestStrcut(t *testing.T){
type S1 struct {
num1 int32
num2 int32
}
type S2 struct {
num1 int32
num2 int16
}
fmt.Println(unsafe.Sizeof(S1{}))
fmt.Println(unsafe.Sizeof(S2{}))
}
// 8 8
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
- 为什么两个结构体的大小是相同的?
# 非内存对齐
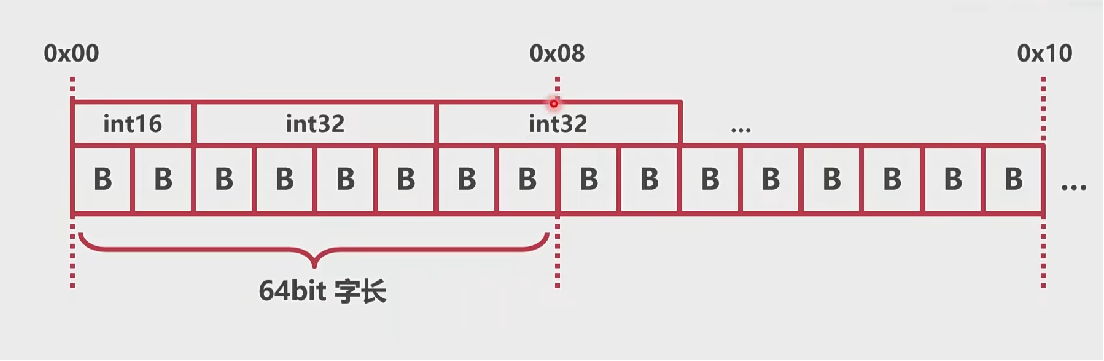
- 非内存对齐:内存的原子性与效率受到影响
# 内存对齐

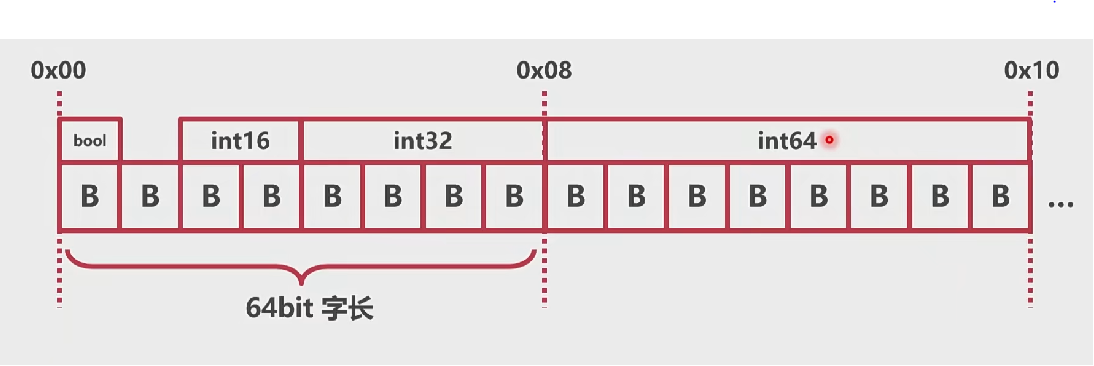
- 内存对齐:提高内存操作效率,有利于内存原子性
# 对齐系数
为了方便内存对齐,Go提供了对齐系数
unsafe.Alignof()1对齐系数的含义是:变量的内存地址必须被对齐系数整除
如果对齐系数为4,表示变量内存地址必须是4的倍数
对齐系数:系统字长与变量长度取小值
# 基本数据类型对齐
func TestAlign(t *testing.T){
fmt.Printf("bool size: %d, align: %d \n", unsafe.Sizeof(bool(true)), unsafe.Alignof(bool(true)))
fmt.Printf("byte size: %d, align: %d \n", unsafe.Sizeof(byte(0)), unsafe.Alignof(byte(0)))
fmt.Printf("int8 size: %d, align: %d \n", unsafe.Sizeof(int8(0)), unsafe.Alignof(int8(0)))
fmt.Printf("int16 size: %d, align: %d \n", unsafe.Sizeof(int16(0)), unsafe.Alignof(int16(0)))
fmt.Printf("int32 size: %d, align: %d \n", unsafe.Sizeof(int32(0)), unsafe.Alignof(int32(0)))
fmt.Printf("int64 size: %d, align: %d \n", unsafe.Sizeof(int64(0)), unsafe.Alignof(int64(0)))
}
//bool size: 1, align: 1
//byte size: 1, align: 1
//int8 size: 1, align: 1
//int16 size: 2, align: 2
//int32 size: 4, align: 4
//int64 size: 8, align: 8
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# 结构体对齐
- 结构体对齐为内部对齐和结构体之间对齐
- 内部对齐:考虑成员大小和成员的对齐系数
- 结构体长度填充:考虑自身对齐系数和系统字长
# 结构体体内部对齐
- 指的是结构体内部成员的相对位置(偏移量)
- 每个成员的偏移量是自身大小与其对齐系数较小值的倍数
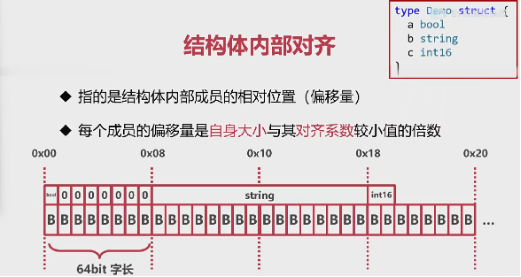
严格遵守结构体内字段的顺序
# 结构体长度填充
- 指的是结构体通过增加长度,对齐系统字长
- 结构体长度是最大成员长度与系统字长较小的整数倍
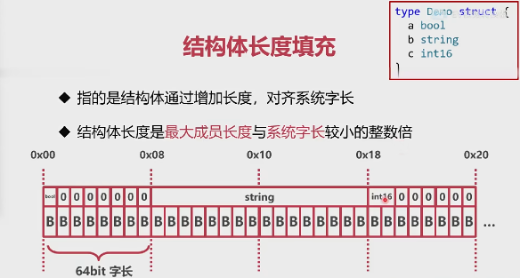
# 结构体对齐系数
- 为什么string的对齐系数是8?
- 刚才Demo结构体,对齐系数是多少?
- 结构体的对齐系数是其成员的最大对齐系数
# 空结构体的对齐
- 空结构体单独出现时,地址为zerobase
- 空结构体出现在结构体中时,地址跟随前一个变量
- 空结构体出现在结构体末尾时,需要补齐字长
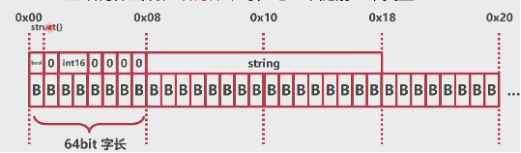
空结构体在末尾时:
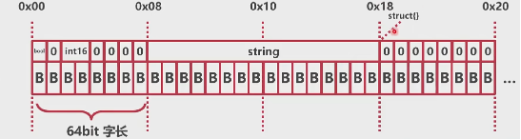
# 总结
- 提高内存操作的效率,变量之间需要内存对齐
- 基本类型考虑对齐系数
- 结构体既需要内部对齐,有需要外部填充对齐
- 空结构体最为最后一个成员,需要填充对齐(防止后面的变量与空结构体共用同一个地址,gc下有危险)
# 小结
# 变量长度
- Go部分数据的长度与系统字长有关
- 空结构体不占用空间
- 空结构体与map结合实现hashset
- 空结构体与channel结合可以当作存信号
# 内存对齐
- 提高内存操作效率,变量之间需要内存对齐
- 基本类型考虑对齐系数
- 结构体既需要内部对齐,又需要外部填充对齐
- 空结构体作为最后一个成员,需要填充对齐
# 字符串与切片
- 字符串与切片都是对底层数组的引用
- 字符串有UTF-8变长编码的特点
- 切片的容量和长度不同
- 切片追加时可能需要重建底层数组
# map
- Go语言使用了拉链实现了hashmap
- 每一个桶中存储了哈希的前8位
- 桶超出8个数据,就会存储到溢出桶中
# map扩容
- 装载系数或者溢出桶的增加,会触发map扩容
- ”扩容“并不是增加桶数,而是整理
- map采用渐进式,桶被操作时才会重新分配
# sync.Map
- map 在扩容时会有并发问题
- sync.Map使用了两个map,分离了扩容问题
- 不会引发扩容的操作(查,改),使用read map
- 可能引发扩容的操作(新增)使用dirty map
# 接口
- Go的隐式接口更加方便系统的拓展和重构
- 结构体和指针都可以实现接口
- 空接口可以承载任何数据
# nil/空结构体/空接口
- nil是多个类型的零值,或者空值
- 空结构体的指针和值都不是nil
- 空接口零值是nil,一旦有了类型信息就不是nil
# 练习
type User struct {
A int32
B []int32
C string
D bool
E struct{}
}
fmt.Printf("User size: %d, align: %d \n", unsafe.Sizeof(User{}), unsafe.Alignof(User{}))
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8