
# 多集群与多租户
- 全链路压测
- 多测试环境
- 生产发部
# 多集群
# 多集群的必要性
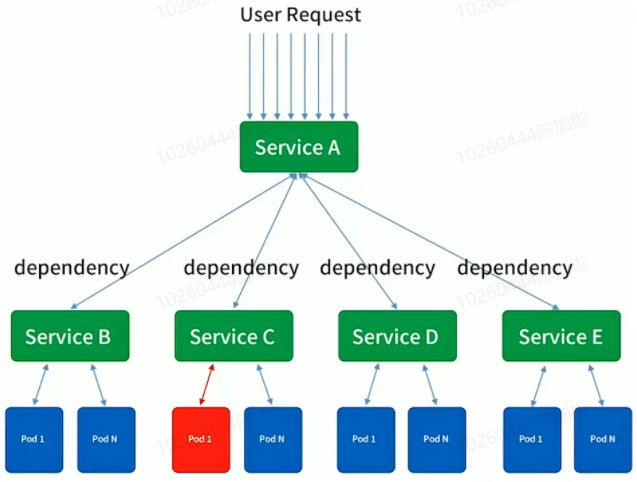
L0 服务,类似像账号服务,之前是一套大集群,一旦故障影响反应巨大,所以从几个角度考虑必要性:
- 单一从节点考虑,多个节点保证可用性,我们通常使用N+2的方式来冗余节点
- 从单一集群故障带来的影响面角度考虑冗余多套集群
- 单个机房内的机房故障导致的问题
多集群实践
k8s平台或者容器平台,在容器启动的时候将Cluster信息注入到容器中,环境变量最终可以去获取出来,当前这个应用处于哪一套集群。
- 应用的管理平台注入到容器
- 环境变量取出来到我们的应用
- 应用最后再把这些元信息,注册到服务发现,注册中心
不同的集群配置文件也可能有区别,所以配置中心一般还支持多机房,多环境,多集群,类似再配置中心也抽象了一个多集群的概念。其实就是他们依赖的cache地址是有区别的。
# 多集群流量切换
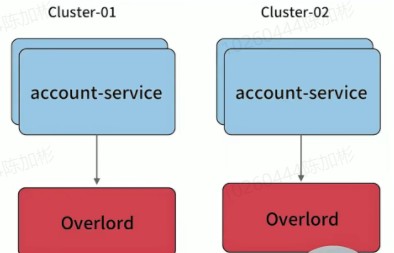
我们利用Pass平台,给某个 appid 服务建立多套集群(物理上相当于两套资源,逻辑上维护cluster的概念),对于不同集群服务启动后,从环境变量里可以获取当下服务的cluster,在服务发现注册的时候,带入这些元信息。当然,不同集群可以隔离使用不同的缓存资源等。
- 多套冗余的集群对用多套独占的缓存,带来更好的性能和冗余能力
- 尽量避免业务隔离使用或者sharding带来的cache hit 影响(按照业务划分集群资源)
案例
Cache Proxy 底层可能是划分两个独占的Cache资源,独占资源带来更好的性能和冗余能力。
- 直播业务用直播账号集群
- 主站业务使用主站账号集群
- 游戏业务使用游戏账号集群
切换带来痛苦,一旦直播账号集群挂了,由于配置文件中指定写死直播业务的账号服务,导致不好切换。
也可以提高一个维度,使用注册中心去做流量切换,导致对注册中心侵入比较大。
即时达到了直播账号集群切主站账号集群,(一次事故中发现)切换以后因为业务隔离,导致集群切换的时候带来了Cache命中率的下降,玩直播的人可能不玩主站,完游戏的人可能不玩直播,导致缓存不热,请求穿透到存储层,数据库压力非常大。
退而求其次,让consumer连接整个Cluster,通过负载均衡,让不同的缓存都预热的不错。当其中一个集群出现大面积问题的时候,将该集群踢下线。这种副作用就小得多。
账号服务作为上游的服务,会有很多的下游服务与其对接,导致连接数过多,深夜的CPU占用量并不低,由于healthCheck。长连接退化成短链接,频繁的建立连接也会带来资源的开销。《Google SRE》这本书里面,它介绍了一个算法,叫子集算法,也叫subset算法。后来发现他的思路非常符合我们的要求。之前的思路是全部连接,现在挑选一些节点去连接。
需要注意:
- 生产者和消费者的变化,如果不能识别,有可能等导致有一些节点的链接数更多,导致cpu不均衡
- 客户端重启或者扩缩容,需要重新均衡
- 均衡算法需要尽可能保证,不应该扩容一个生产者,缩容一个consume导致大面积的重联
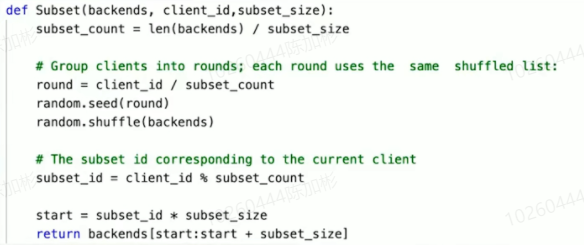
子集算法
- 把backends的所有连接拿过来
- 设定一个你期望的子集大小
- 根据期望的大小,将backends划分成好多块
- 让每一个不同的消费者用一套洗牌算法,把它重新排序
- 获取一个种子,如:使用消费者节点的ip端口做哈希
- 使用自身种子,去其中获取连接,尽量将所有的连接均匀分布
# 多租户
# 多系统共存
在一个微服务架构中允许多个系统共存是利用微服务稳定性及模块化最有效的方式之一,这种方式一般被称为多租户。租户可以是测试,金丝雀发布,影子系统,甚至服务层或者产品线,使用租户能够保证代码的隔离性并且能够基于流量租户做路由决策。
对于传输中的数据(例如,消息队列中的请求或者消息)以及静态数据(例如,存储或者持久化缓存),租户都能够保证隔离性和公平性,以及基于租户的路由机会。
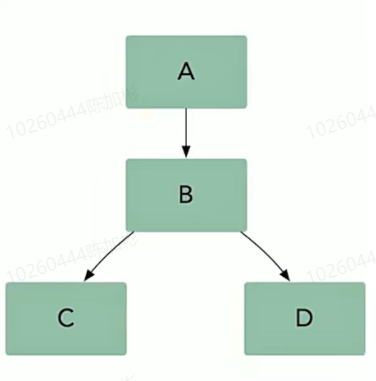
如果我们对服务B做出改变,我们需要确保它仍然能够和服务A,C,D正常交互。在微服务架构由两种基本的集成测试方式:并行测试和生产环境测试。
在微服务架构中,我们允许多系统共存,什么叫多系统共存?
- 同一个服务有多个不同的版本,让一个流量路由到各种不同的版本,我们一般把这种允许多系统共存的方式叫做多租户。
- 租户可以是某一种测试环境,可以是金丝雀发布,所谓的预发布,也可以是影子系统叫Shadow System。
- 影子系统一般用于全链路压测,因为你知道全链路压测在线上压测,你肯定期望不影响能检验生产环境,但是又不影响生产环境,你希望一套完整的测试环境能够虚拟出来,压的是线上的资源,但是又不影响在线的业务。
- 甚至我希望在线上去演练整个完整功能的时候,不影响在线业务。这个流量只能由测试的同学能够引起,但是线上用户不影响。用户在生产环境的时候,你如何能做到你的RPC,一部署服务,流量就进来了。
- 有没有办法实现类似像租户的方式,保证代码的隔离,并且基于流量租户来做一个路由决策。
案例说明
集成测试中 B 改变成 B‘ 对系统的影响
- 这种情况下,就有可能一套测试环境就无法满足。
- 在线上做生产环境测试话,其实是由风险的,即使使用灰度发部,只发部一个容器,那也会影响部分流量。
- 有些公司使用 01、02、03多套测试环境,各自微服务的测试提前招呼,这也很难保证测试环境中的代码不被冲掉。
并行测试环境不好维护,多套不好搭建
- 混用测试环境导致的不可靠测试
- 多套环境带来的硬件成本
- 难以做负载测试,仿真线上的正式流量情况
# 染色发部
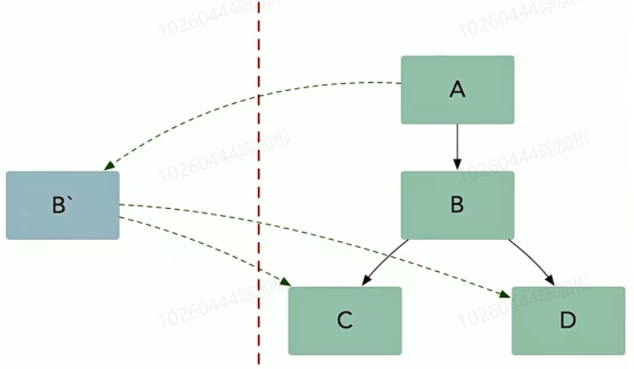
- B’放入到沙箱环境中运行,但是B'可以访问之前稳定的集成测试环境。
- 让测试的流量到B',但是正常的流量还在B中
- 需要做流量的路由
染色实践
B‘怎么知道自己是特殊的发布呢?
- k8s的管理平台,包括发部平台,在测试的时候,把B’的发部当成一次染色发布,比方叫 高级功能001,进行部署
- 发布时就像多集群一样,打入标签到环境变量里面,让其注册到注册中心。
- RPC框架需要怎么办?需要支持在做负载均衡,在做节点筛选的时候,正常流量取节点默认取染色等于空的。
- 构建连接池的时候构建多个连接池子,可以使用map维护
- 这种构建的方式对线上是没有影响的,但是灰度发布其实对线上是有影响的。
- 预发布或者回归测试即使在线上玩实际上对用户是没有影响的。(update数据影响是有的)
如果需要好用,最好需要把染色信息打到日志,消息队列,缓存和配置中去。
这种方式构建出来的架构,对数据库缓存等中间件是有一定依赖的。
- redis使用不同db
- 数据库表明切换如xxx_mirror
- 消息队列建立新的topic
- 银行或者短信的这种,对用户会有打扰,最好需要mock掉
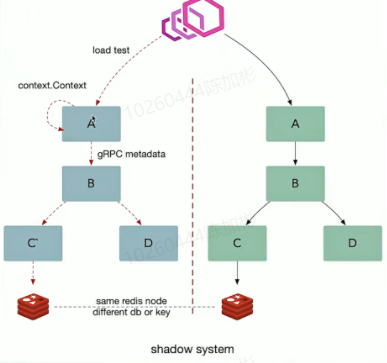
给入站的请求绑定上下文(如:HTTP Header),in-proccess 使用 context 传递,跨服务使用 metadata 传递(如:opentracing baggage item),在这个架构中每一个基础组件都能够理解租户信息,并且能够基于每一个基础组件都能够理解租户信息,并且能够基于租户路由隔离流量,同时在我们的平台中允许对运行不同的微服务由更多的控制,比如指标和日志。在微服务架构中典型的基础组件时日志,指标,存储,消息队列,缓存以及配置。基于租户信息隔离数据需要分别处理这些基础组件。
多租户架构本质描述为:
跨服务传递请求携带上下文(context),数据隔离的流量路由方案
利用服务发现组测租户信息,组测成特定的租户。
← 微服务设计